For more about my experiences, please check out my
CV.
My research interests span the theoretical and practical aspects of signal processing and
machine learning. I focus on bridging theory and practice in deep learning by developing
theory for modern paradigms such as multi-task learning and implicit neural
representations, and using these insights to guide the design of practical systems. More
recently, I have become interested in the foundations of large language model pretraining,
including optimization dynamics, memorization, and generalization in large-scale models.
Publications
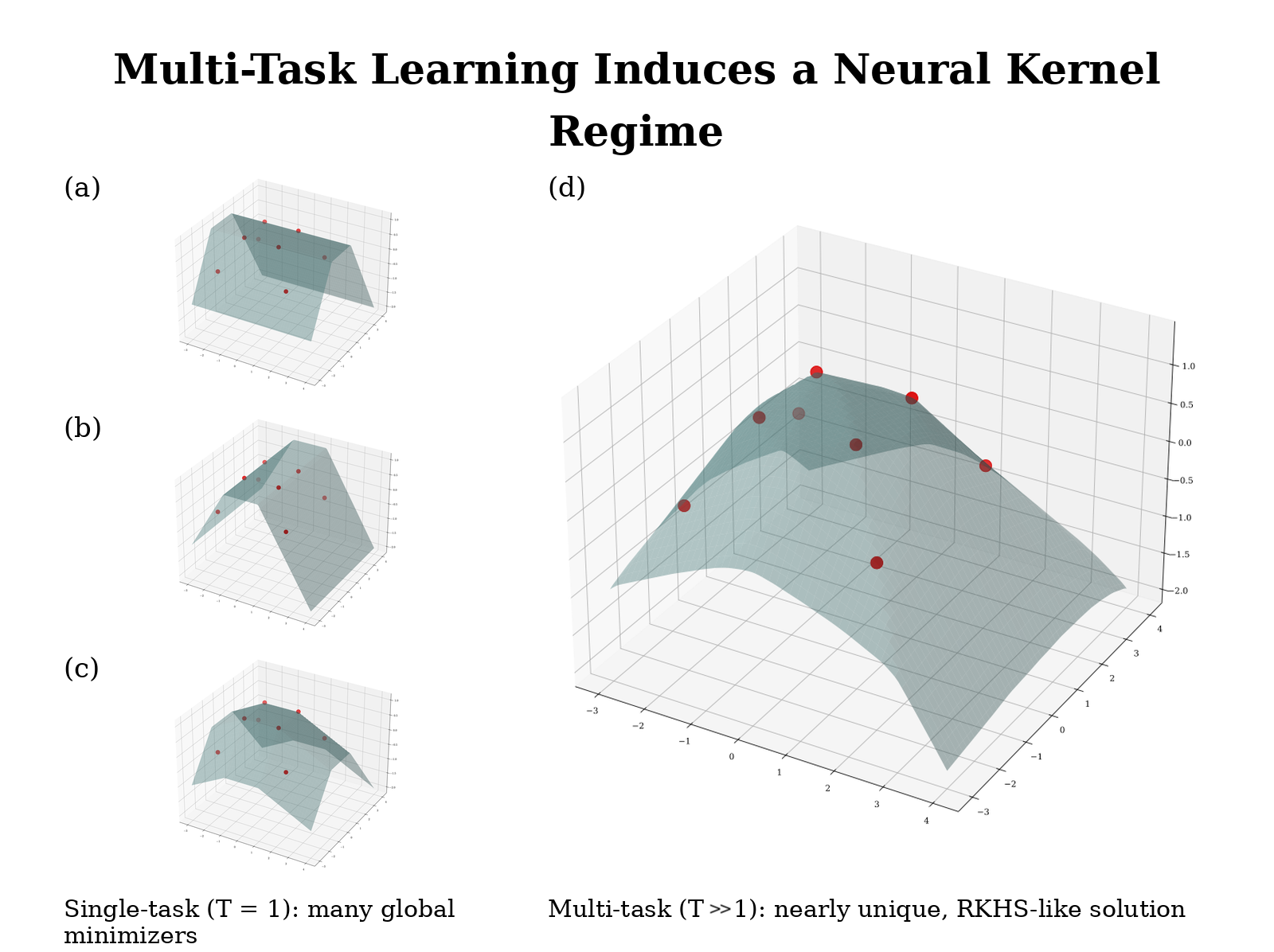
A New Neural Kernel Regime: The Inductive Bias of Multi-Task Learning
Julia Nakhleh, Joseph Shenouda, Robert D. Nowak.
Advances in Neural Information Processing Systems (NeurIPS) 2024
We show that when a neural network is trained on many tasks at once, it behaves much more predictably and produces a unique, smooth solution — similar to classical kernel methods. In contrast, training on a single task can lead to many very different solutions, even when they fit the data equally well.
Variation Spaces for Multi-Output Neural Networks: Insights on Multi-Task Learning and Network Compression
Joseph Shenouda, Rahul Parhi, Kangwook Lee, Robert D. Nowak.
Journal of Machine Learning Research (JMLR) 2024
We introduce a variation space framework that explains how multi-output ReLU networks share structure across tasks in multi-task learning. This leads to principled methods for improving generalization and compressing networks without sacrificing performance.
ReLUs Are Sufficient for Learning Implicit Neural Representations
Joseph Shenouda, Yamin Zhou, Robert D. Nowak.
International Conference on Machine Learning (ICML) 2024
We show that standard ReLU activations yield an ill-conditioned loss landscape for INR problems. We then propose a B-spline wavelet–inspired modification to ReLU and demonstrate its effectiveness on standard INR tasks. Finally, we connect these findings to my prior work on measuring function regularity for efficient hyperparameter selection.
Trained and analyzed 0.5B–1B parameter LLMs under Warmup–Stable–Decay (WSD) and Cosine LR schedules in controlled pretraining settings.
Designed synthetic factual injection datasets to isolate memorization, forgetting, and consolidation across pretraining phases.
Demonstrated that factual consolidation under WSD is confined to cooldown, while Cosine is injection-time invariant at matched loss.
Developed scheduler-aware diagnostics based on relative weight update magnitude to predict knowledge acquisition capacity.
Built custom datasets, training hooks, and evaluation metrics for token-level factual retention.
NEC Research Labs — Machine Learning Research Intern
Summer 2025
Researched mathematical foundations for in-context learning in Large Language Models (LLMs).
Developed theoretical constructions for how LLMs can learn in-context models and conducted computational experiments to verify the theory.
MIT Lincoln Laboratory — Summer Research Intern
Summer 2021
Teaching
University of Wisconsin–Madison
(Teaching Assistant) ECE/CS 761: Mathematical Methods in Machine Learning — Spring 2024. Delivered 3 lectures throughout the semester and organized weekly problem solving sessions.
(Teaching Assistant) ECE 203: Signals, Information and Computation — Fall 2024. Prepared weekly lab assignments and assisted students through weekly office hours. Awarded the ECE 2025 TA Excellence Award for outstanding performance.
(Teaching Assistant) ECE 888: Nonparametric Methods in Data Science — Spring 2025.
(Teaching Assistant) ECE 532: Matrix Methods in Machine Learning — Spring 2026.
Workshop Papers
A Representer Theorem for Vector-Valued Neural Networks: Insights on Weight Decay Training and Widths of Deep Neural Networks
Joseph Shenouda, Rahul Parhi, Kangwook Lee, Robert D. Nowak.
International Conference on Machine Learning (ICML) Duality Principles for Modern ML Workshop (contributed talk)